Links
- arxiv cs.DC 2021-11-04 https://arxiv.org/pdf/2111.03065.pdf
主要内容
Problem
- GPU软件栈过大(数十MB)、部分代码依赖于POSIX层
- 移植GPU软件栈工程量大、使TCB膨胀、引入新的安全问题
- 将运算外包到普通世界的GPU软件栈,需要防止数据/模型参数被学习/结果篡改:同态加密、ML工作负载转换、结果验证。
Key idea
提出一种名为协作试运行(collaborative dryrun, CODY)的方法,实现了一种记录CPU和GPU交互的环境
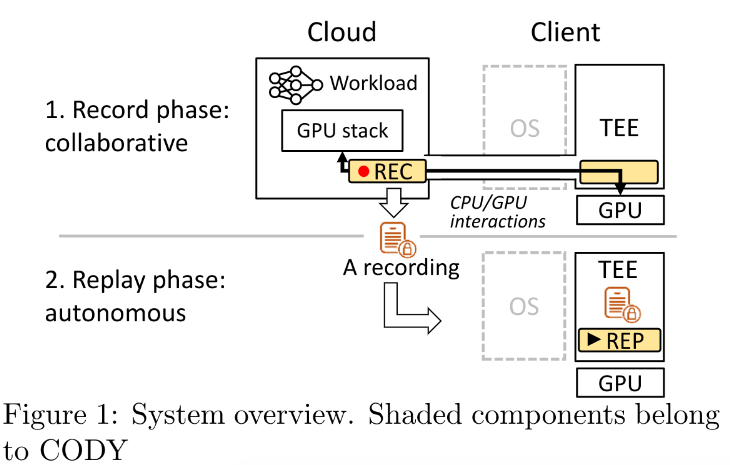
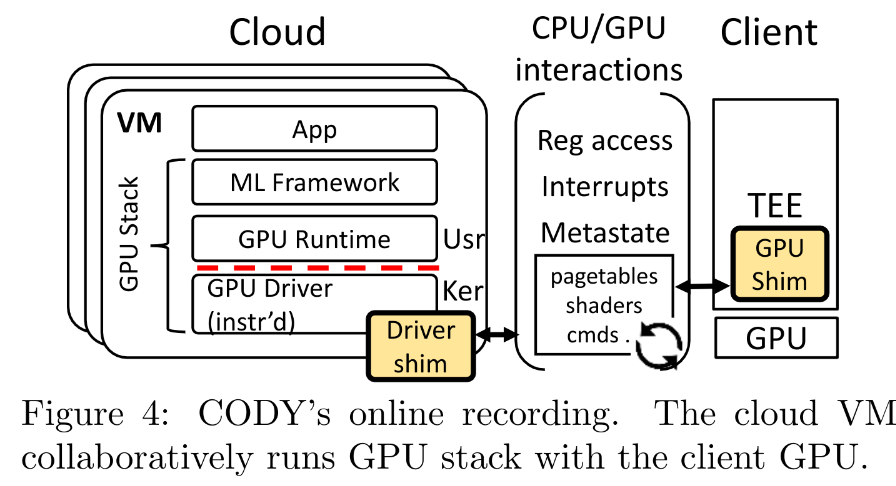
记录阶段:
云服务运行GPU软件栈,而无任何GPU硬件
Client端TEE中的程序请求云服务运行一个负载(例如一个模型推断任务)
云服务中在没有实际GPU硬件的情况下执行GPU软件栈,将CPU和GPU之间的交互传递到Client端的TEE程序中(协作)
云服务记录对于该负载的所有的GPU交互
重放阶段:
- 对于新的输入,TEE在没有云服务交互的情况下,在物理GPU上重放之前的记录
优点:
- 安全、可管理的记录环境,云服务运行在严格管理的基础设施上运行,与客户端TEE之间执行经过验证的加密通信
- 云服务不会知道TEE的敏感数据:模型输入、模型参数
- 云服务可以访问不同的GPU硬件而无需托管它们,而是负责托管GPU硬件的驱动程序
Challenges and Designs
Challenges
- 跨越Cloud和Client之间的连接的CPU/GPU之间的交互。时延问题
- registerr accesses、accesses to shared memory、interrupts
Designs
提出两个见解:
- GPU的寄存器访问序列包含许多重复的段:可以预测寄存器访问及结果
- Cloud只需要产生可重放的交互序列,不需要保证正确性
设计上,CODY会自动化地插桩GPU驱动代码,以实现:
- 寄存器访问的推迟:将多个寄存器访问请求批量提交给Client;将未提交的寄存器读请求表示为符号(symbol),允许驱动程序的符号执行(symbolic execution of the driver),在Client返回结果后使用具体的寄存器值替换符号变量(symbolic variables)
- 寄存器访问的预测:预测寄存器读的结果,并允许驱动用预测的结果继续执行;在Client返回结果后验证预测是否正确;如果预测失败,cloud和client端都使用GPU重放技术快速回滚到他们最近的有效状态
- 仅metastate(元状态?)的同步(Metastate-only synchronization):cloud和client必须保持内存同步;通过挖掘GPU硬件事件减少同步频率;通过仅同步GPU的metastate(如GPU shaders, command lists, and job descriptions),省略构成GPU内存的大部分工作负载数据;确保交互的正确性,放弃计算结果的正确性
Environment
- Cloud:Odroid C4,Arm board,
- GPU栈:a ML framework (ACL v20.05), a runtime (libmali.so), a driver (Mali Bifrost r24)
- Client:Hikey960 with Mali G71 MP8 GPU
- Debian 9.13(Linux v4.19), OPTEE (v3.12)
- 使用多种不同的ML负载
威胁模型
- 信任cloud,信任其上的GPU堆栈,信任client端的TEE
- 威胁:客户端TEE之外部分的威胁、来自网络通信窃听的威胁
实现
- 代码插桩工具:实现为一个Clang plugin,静态分析和代码修改,分析驱动程序的抽象语法树
- DriverShim:1K SLoC,内核模块,由被插桩后的驱动程序调用、执行依赖跟踪、提交的管理、预测
- GPUShim
Details
CPU/GPU之间的交互类型
- 寄存器
- 共享内存(包括GPU专用的页表,可以映射到GPU内存或CPU内存)
- 来自GPU的中断
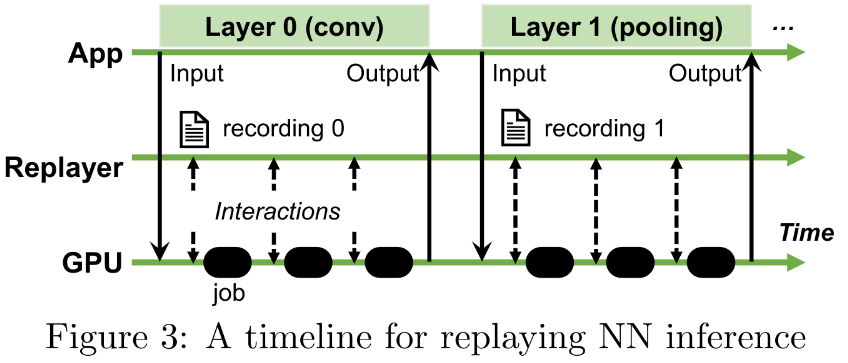
重放流程
- TEE中内置一个简单的replayer(30KB)
- 可以选择创建一整个recording,也可以选择一次记录中为模型的每个层分别创建recordings:
优化技术
推迟寄存器访问(5b)
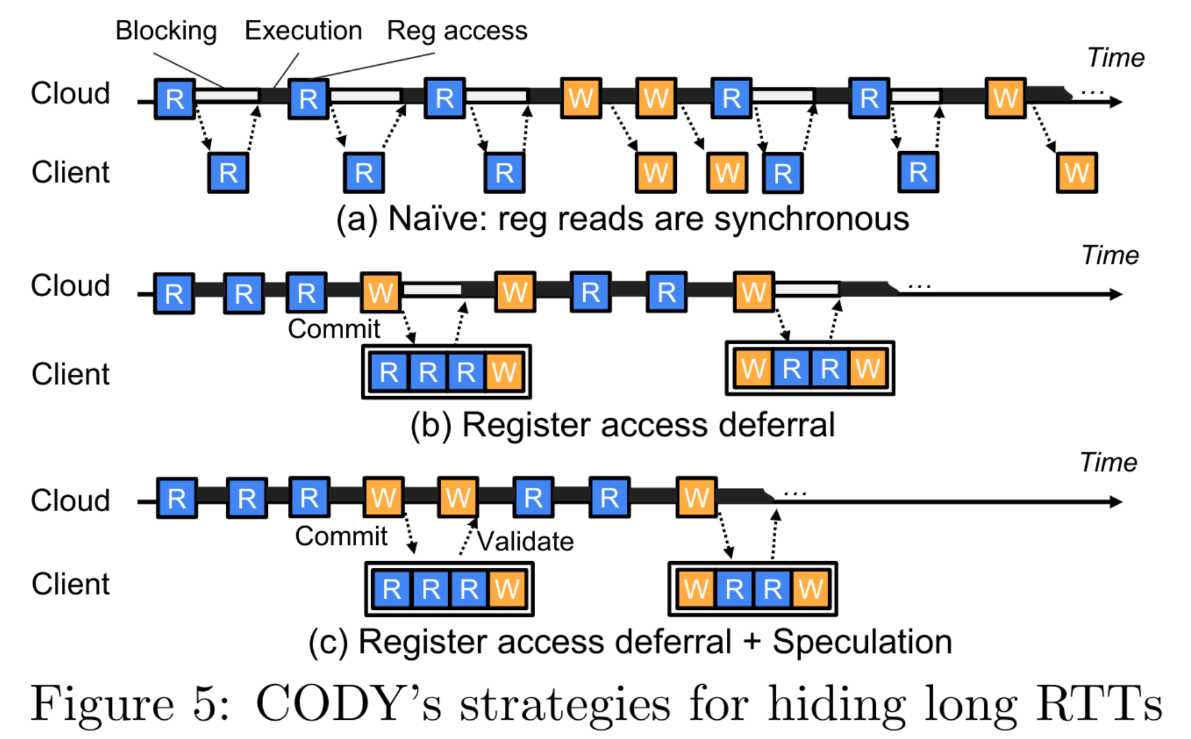
- 持续执行,直至驱动无法在没有真实的值的情况下继续执行下去,驱动暂停
- 此时cloud端异步地提交(commit)所有被推迟访问的的请求
- 实现:通过自动化工具向驱动注入hook函数
- 正确性:
- 访问的正确性
- client端寄存器访问顺序需保持一致
- 处理寄存器访问触发的隐藏依赖,例如读中断寄存器可能自动清空中断状态
- 处理:每个内核线程对应一个队列
- 数据依赖&控制依赖
- 读不存在、读后写、读后分支
- 用符号(symbol)替代读的结果,并传播到后续的使用中,在提交返回时将这些符号替换为具体值
- 访问的正确性
- 提交时机
- 分支逻辑依赖于读寄存器值
- 调用内核api,尤其是scheduling、locking等
- 驱动明确地调用了延迟函数
- 如何保证多线程的一致性?
- 假定驱动程序用锁来更新共享变量
- 在释放锁之前提交
预测(5c)
- 提交后不阻塞等待、而是继续执行
- 用预测的提交C中的寄存值来继续执行;当提交返回后再进行验证,如果预测失败则进行恢复。不影响正确性
- 保守预测:只在该位置最近的k次提交都给出一样的返回时,才运行使用预测的结果,实验中k=3
- 正确性:
- 新提交在已有提交返回并验证后发出
- 发生内核状态外化时(如printk),阻塞执行:通过拦截十几个外化API来实现(可能不够全面)
- 跟踪预测值寄存器的访问:寄存器染色、污点跟踪
- 预测失败的恢复
- CPU/GPU状态都要恢复
- cloud向client发送发生错误预测的位置,双方使用记录的日志重放,快速重新启动,期间不需要通信
卸载轮询循环(Offloading polling loops)
- 将一些循环polling的情况一次性卸载到client端
选择性内存同步
- 问题:CPU和GPU的内存共享协议方法未被明确定义,不使用锁
- 思路:将GPU任务数量限制为1,使CPU和GPU串行执行,不会同时访问共享内存
- 时机:
- cloud→client:启动新的GPU作业之前
- client→cloud:客户端发出作业完成的中断
实验
性能部分
四种策略:Naive、OursM、OursMD、OursMDS(完整的CODY)
两种场景:Wifi、蜂窝网络
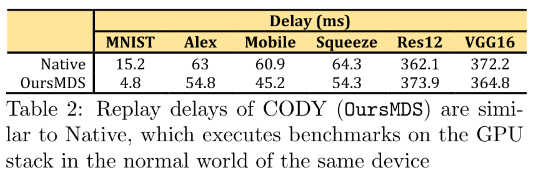
六种模型:MNIST、Alex、Mobile、Squeeze、Res12、VGG1
- 比较Recording delays
- Naive+wifi: 52秒-423秒
- OursMDS:用时平均减少95%,18秒(Wifi),30秒(蜂窝网络)
- 比较Replay delays
使用CODY重放,比直接在普通世界运行GPU堆栈减少了3%-68%的时间